20.109(S16):In situ cloning (Day1)

Introduction
Though the theme of Module 1 is protein engineering, today will focus on a few key techniques used in DNA engineering. Because the sequence of proteins is determined by the sequence of the genes that encode them, learning how to manipulate DNA is an important first step. Today you will complete a cloning reaction to generate a protein expression vector that contains a gene that encodes a calcium-sensing protein. This process is illustrated in the schematic below. Later you will use this construct to engineer a new calcium-sensing protein.

The cloning vector we will use is pRSET. This vector has several features that make it ideal for cloning and protein expression -- both of which are important for this module. The calcium-sensing protein we will study in Module 1 is inverse pericam (IPC). We will discuss this protein in much more detail later, for now it is sufficient to know that IPC was engineered to measure calcium concentrations. To generate your final product you will use three common DNA engineering techniques: PCR amplification, restriction enzyme digestion, and ligation.
PCR amplification
The applications of PCR (polymerase chain reaction) are widespread, from forensics to molecular biology to evolution, but the goal of any PCR is the same: to generate many copies of DNA from a single or a few specific sequence(s) (called the “target” or “template”).
In addition to the target, PCR requires only three components: primers to bind sequence flanking the target, dNTPs to polymerize, and a heat-stable polymerase to carry out the synthesis reaction over and over and over. DNA polymerases require short initating pieces of DNA (or RNA) called primers in order to copy DNA. In PCR amplification, forward and reverse primers that target the non-coding and coding strands of DNA, respectively, are separated by a distance equal to the length of the DNA to be copied. Length is one important design feature. Primers that are too short may lack requisite specificity for the desired sequence, and thus amplify an unrelated sequence. The longer a primer is, the more favorable are its energetics for annealing to the template DNA, due to increased hydrogen bonding. On the other hand, longer primers are more likely to form secondary structures such as hairpins, leading to inefficient template priming. Two other important features are G/C content and placement. Having a G or C base at the end of each primer increases priming efficiency, due to the greater energy of a GC pair compared to an AT pair. The latter decrease the stability of the primer-template complex. Overall G/C content should ideally be 50 +/- 10%, because long stretches of G/C or A/T bases are both difficult to copy. The G/C content also affects the melting temperature. PCR is a three-step process (denature, anneal, extend) and these steps are repeated 20 or more times. After 30 cycles of PCR, there could be as many as a billion copies of the original target sequence.

Based on the numerous applications of PCR, it may seem that the technique has been around forever. In fact it is just over 30 years old. In 1984, Kary Mullis described this technique for amplifying DNA of known or unknown sequence, realizing immediately the significance of his insight.
"Dear Thor!," I exclaimed. I had solved the most annoying problems in DNA chemistry in a single lightening bolt. Abundance and distinction. With two oligonucleotides, DNA polymerase, and the four nucleosidetriphosphates I could make as much of a DNA sequence as I wanted and I could make it on a fragment of a specific size that I could distinguish easily. Somehow, I thought, it had to be an illusion. Otherwise it would change DNA chemistry forever. Otherwise it would make me famous. It was too easy. Someone else would have done it and I would surely have heard of it. We would be doing it all the time. What was I failing to see? "Jennifer, wake up. I've thought of something incredible." --Kary Mullis from his Nobel lecture; December 8, 1983
Restriction enzyme digest

Restriction endonucleases, also called restriction enzymes, 'cut' or 'digest' DNA at specific sequences of bases. The restriction enzymes are named according to the prokaryotic organism from which they were isolated. For example, the restriction endonuclease EcoRI (pronounced “echo-are-one”) was originally isolated from E. coli giving it the “Eco” part of the name. “RI” indicates the particular version on the E. coli strain (RY13) and the fact that it was the first restriction enzyme isolated from this strain.
The sequence of DNA that is bound and cleaved by an endonuclease is called the recognition sequence or restriction site. These sequences are usually four or six base pairs long and palindromic, that is, they read the same 5’ to 3’ on the top and bottom strand of DNA. For example, the recognition sequence for EcoRI is below (see also figure at right). EcoRI cleaves the phosphate backbone of DNA between the G and A of the recognition sequence, which generates overhangs or 'sticky ends' of double-stranded DNA.
5’ GAATTC 3’
3’ CTTAAG 5’
Unlike EcoRI, some other restriction enzymes cut precisely in the middle of the palindromic DNA sequence, thus leaving no overhangs after digestion. The single-stranded overhangs resulting from DNA digestion by enzymes such as EcoRI are called sticky ends, while double-stranded ends resulting from digestion by enzymes such as HaeIII are called blunt ends. HaeIII recognizes
5’ GGCC 3’
3’ CCGG 5’
Ligation
In a ligation reaction, DNA ends are covalently attached to one another via the ligase enzyme. The efficiency of the reaction is related to type of DNA ends: compatible sticky ends will ligate more efficiently than blunt ends, and non-compatible sticky ends will not be ligated due to the lack of hydrogen bonding between the basepairs. To initiate the ligation reaction, hydrogen bonds are formed between the compatible overhangs of DNA fragments. The ligase enzyme then forms a covalent phosphodiester bond between the 3' hydroxyl end of the 'acceptor' nucleotide and the 5' phosphodiester end of the 'donor' nucleotide.

The first step in this process is the addition of AMP (adenylation) to a lysine residue within the active site of DNA ligase, which releases a pyrophosphate. Next, the AMP is transferred to the 5' phosphate of the donor nucleotide resulting in the formation of a pyrophosphate bond. Lastly, a phosphodiester bond is formed between the 5' phosphate of the donor nucleotide and the 3' hydroxyl of the 3' acceptor nucleotide.
Protocols
Part 1: Laboratory orientation quiz
Complete the orientation quiz with your partner. Though you are working with your partner, each student should record all answers on the provided quiz. If you disagree with your partner on an answer, you should write what you think is the correct answer on your quiz.
Good luck!
Part 2: PCR amplification and restriction enzyme digest of IPC insert
Because DNA engineering at the benchtop can take days, if not weeks, you will generate your clone in silico today. You can use any DNA manipulation software you choose to complete the protocols, but the instructions provided are for APE (A Plasmid Editor, created by M. Wayne Davis at the University of Utah). The software can be downloaded free-of-charge from this site onto your personal computer or you can use the 20.109 laboratory computers. Please note that if you use a different program the teaching faculty may not be able to assist you.
Be sure to document your work and answer all questions in your lab notebook as you progress through the exercises below.

To amplify a specific sequence of DNA, you first need to design primers -- one primer that anneals at the start of the sequence of interest and a second primer that anneals at the end of the sequence of interest. Today you will design a 'forward' primer that anneals to the non-coding DNA strand and reads toward the IPC gene and a 'reverse' primer that anneals to the coding DNA strand at the end of the IPC gene and reads back into it. Each primer will consist of two parts: the 'landing sequence' will anneal to the sequence of interest and the 'flap sequence' will be used to add a restriction enzyme recognition sequence to your IPC insert.
- Find the IPC insert sequence here.
- Open APE then copy and paste the sequence into a new workspace.
- Record the size of the IPC gene in your notebook.
- Because we want to amplify the entire gene, the landing sequence of the forward primer will begin with the first basepair of the sequence.
- Record the first 20 basepairs of the IPC gene sequence in your notebook.
- Several websites are available to help you evaluate the characteristics of your primer. We will use the Oligoanalyzer tool provided by Integrated DNA Technologies (IDT).
- Copy and paste the 20 basepair sequence into Sequence box at the IDT website.
- Leave the defaults for stems and loops as they are and then click Analyze.
- Use the following guidelines to evaluate your primer:
- length: 17-28 basepairs
- GC Content: 50-60%
- Tm: 60-65°C
- avoid hairpins, complementation between primers, and repetitive sequences
- If you primer does not fit the guidelines provided above, try altering the length. Remember that the 5’ end of the landing sequence must not change or you will delete basepairs from your gene.
- When you are satisfied with the landing sequence, use the Features tool to label the forward primer sequence on your APE file (Features → New Feature).
- Now that you have your landing sequence you will add a flap sequence that introduces a restriction enzyme recognition sequence.
- As shown in the schematic of our cloning strategy, we need to add a BamHI recognition sequence to our forward primer. Search the NEB catalog to find the BamHI recognition sequence. Record the recognition sequence and the cleavage sites within the sequence.
- Add the recognition sequence for the BamHI restriction enzyme to the landing sequence. Consider the direction in which PCR amplification occurs to determine which end of your primer should carry the flap sequence.
- For reasons that will be evident later, you must also include an extra basepair between the BamHI recognition sequence and your landing sequence. Add a 'T' at this location in your primer.
- In addition to the recognition sequence, it is important to include a 6 basepair 'tail' or 'junk' sequence to ensure the restriction enzyme is able to bind and cleave the DNA. Learn more about why this is necessary from scientists at NEB. Add any sequence of 6 basepairs to your primer flap sequence. Carefully consider where this sequence should appear in your primer.
- Record the sequence (5' → 3') of your forward primer in your notebook.
- Use steps 2-5 to design your reverse primer. Please keep the following notes in mind:
- Because you want to amplify the entire gene you should start with the last basepair of the sequence.
- Do NOT add a 'T' between the enzyme recognition sequence and your landing sequence.
- You will add an EcoRI restriction recognition site to your reverse primer.
- Remember that the reverse primer anneals to the coding DNA strand at the end of the IPC gene and reads back into it. Keep this in mind when you add the flap sequence and when you record the sequence (5' → 3') of your primer in your notebook.
- Create a new APE file that depicts the IPC product you would expect if you used your primers in a PCR amplification reaction.
- What is the size of your PCR product? How does this compare to the size of the gene you recorded in Step #1.
- Add the sequence information to your notebook (it may be easiest to screen capture your work station in APE and embed the image in your notebook).
- Now that you have your amplified IPC insert, you need to digest with BamHI and EcoRI to generate 'sticky ends' that will enable you to ligate your insert into the pRSET vector.
- Create another new APE file that depicts your amplified IPC product following a BamHI and EcoRI double-digest.
- What is the size of your digest product? How does this compare to the size of your PCR product?
Part 3: Restriction enzyme digest of pRSET vector
To prepare for the ligation step, it is important to generate compatible 'sticky ends' on the insert and vector. Above, you digested your IPC amplicon (PCR amplification product) with BamHI and EcoRI in a double-digest. Here you will digest your pRSET vector to create compatible ends that can be ligated together.

- Find the pRSET vector sequence here.
- Copy and paste the vector sequence into a new APE workspace.
- Commercially available cloning vectors are engineered to contain a Multiple Cloning Site (MCS). The MCS is a short segment of DNA that encodes several restriction enzyme recognition sites. These restriction enzyme recognition sites are provided for so researchers can clone their genes of interest into a specific location of the vector.
- Using the Feature tool, label basepairs 192-248 as the MCS.
- To locate the BamHI and EcoRI recognition sequences within the MCS, go to Enzymes → Enzyme selector.
- Select EcoRI and click Graphic Map. An image of the plasmid should appear in a separate window with the recognition sites marked. In addition, the recognition sequences should be highlighted in the sequence that is in your workspace.
- Using the feature tool, label the BamHI and EcoRI recognition sequences.
- Save your labelled pRSET file.
Part 4: Ligation of IPC insert and pRSET vector
When you complete a ligation at the bench, one very important step is to calculate the amounts of DNA you will use in the reaction. Use the steps below to calculate the amount of IPC insert and pRSET vector you would use to complete this ligation in the laboratory.

- Calculate the concentration of backbone and of insert you would use in a ligation reaction based on the recovery gel posted on the right.
- For both the insert and the vector, 5 μL of DNA was loaded into the gel.
- Refer to the NEB marker definitions to determine the ng of DNA in each lane. Note that the ng listed are for 10 μL of ladder and in the gel shown we loaded 20 μL of ladder.
- Convert the mass concentration to a molar concentration, using the fact that a typical DNA base is 660 g/mol. This conversion will mostly cancel out between the insert and the backbone, except for the difference in number of bases. Feel free to either omit steps that will cancel if you are comfortable doing so, or to keep them if you follow the math better that way.
- Ideally, you will use 50-100 ng of backbone in the this ligation.
- Referring to the mass concentration, what volume of DNA will this amount require?
- Ideally, you will use a 4:1 molar ratio of insert to backbone.
- Referring to the molar concentrations, how much insert do you need per μL of backbone?
- A 15 μL scale ligation should not include more than 13.5 μL of DNA because you must leave enough volume to add buffer and the ligase enzyme.
- If your backbone and insert volumes total to greater than this amount, you must (1) scale down both DNA amounts, using less than 50 ng backbone and/or (2) stray from the ideal 4:1 molar ratio. You may ask the teaching faculty for advice during class if you are unsure what choice is best.
- Be sure to record all of your work for the ligation calculations in your notebook.
- Feel free to take a picture of your hand-written work and embed the image in your notebook.
- Next you will complete this ligation in silico to generate a plasmid map of your pRSET-IPC plasmid.
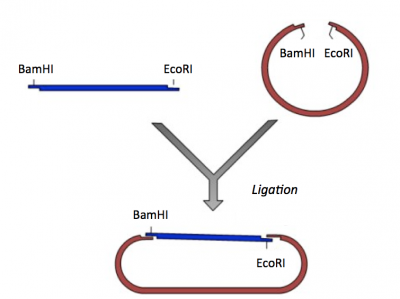 Ligation of IPC insert and pRSET vector.
Ligation of IPC insert and pRSET vector.
- To ligate your IPC fragment into your pRSET vector, copy the digested IPC sequence you generated above and paste it into your vector sequence.
- Recall where BamHI and EcoRI cut within their recognition sequences as you consider the exact basepairs between which you should paste your IPC insert.
- Hint: the IPC insert should be flanked by intact BamHI and EcoRI recognition sequences in your final cloning product.
- Save the file of your pRSET-IPC and embed the plasmid map image in your notebook.
- Now that you have generated your pRSET-IPC clone, discuss the following questions with your partner and record your answers in your notebook.
- Recall the 'T' that you added between the landing sequence and the BamHI recognition sequence of your forward primer. What is the purpose of this additional basepair?
- Hint: Think about the spacing between the His tag (CATCATCATCATCATCAT) and the first codon of the IPC gene in your plasmid map. This His tag will be incorporated onto the translated protein sequence and enable you to purify your protein using affinity chromatography.
- Why was a 'T' not added between the landing sequence and the EcoRI recognition sequence of your reverse primer?
- Why did you use two different restriction enzymes in the cloning strategy?
- Recall the 'T' that you added between the landing sequence and the BamHI recognition sequence of your forward primer. What is the purpose of this additional basepair?

Part 5: Confirmation digest
To confirm the pRSET-IPC construct that we will use for this module, you will perform a 'diagnostic' or 'confirmation' digest. Recall from lecture that this step is important as a control -- you want to be sure that the products you use in your research are correct. This is an important step to check products you clone yourself and, perhaps more importantly, those that you may receive from another researcher.
Ideally you will use a single enzyme that cuts once within the vector and once within your insert. Unfortunately, this is rarely an option and you instead need to select an enzyme that cuts once within the vector and a second, compatible enzyme that cuts once within the insert. Enzyme compatibility is determined by the buffer. If two enzymes are able to function (cleave DNA) in the same buffer, they are compatible. The NEB double digest online tool will prove very helpful!
Use information from the lab manual, the NEB catalog and the plasmid map you generated above to choose the enzymes you will use. The following table may be helpful as you plan your work.
Keep the following in mind as you consider which enzymes to use:
- Each enzyme should be present in 2.5 U quantity. As an example, the XbaI vial contains 20,000 U/mL, or 20 U/μL, that is to say 8 times the desired working quantity in one microliter; therefore one reaction will require 0.125 μL.
- Because the lower limit of your pipet is 0.5 μL, you will need to dilute the enzyme in its appropriate buffer prior to adding it to your master mix.
- The 20.109 enzyme stocks are always the "S" size and concentration.
| Diagnostic digest | Enzyme 1 only | Enzyme 2 only | No enzyme (uncut) | |
|---|---|---|---|---|
| pRSET-IPC | 5 μL | 5 μL | 5 μL | 5 μL |
| 10X NEB buffer | 2.5 μL of buffer#_____ | 2.5 μL of buffer#_____ | 2.5 μL of buffer#_____ | 2.5 μL of buffer#_____ |
| 1st Enzyme (2.5 U) | ____ μL of _____ | ____ μL of _____ | ||
| 2nd Enzyme (2.5 U) | ____ μL of _____ | _____ μL of _____ | ||
| H2O | to a final volume of 25 μL (not including volume of enzyme) | |||
- Unlike the cloning steps you completed above, the diagnostic digest will be performed at the benchtop.
- Prepare a reaction cocktail for each of the above reactions (uncut, singly cut with enzyme 1, singly cut with enzyme 2 and doubly cut with enzyme 1 and enzyme 2) that includes (in that order) water, buffer and enzyme.
- Aliquot 5 μL of pRSET-IPC into four well-labeled eppendorf tubes.
- The labels should include the plasmid name, the enzymes to be added, and your team color.
- Add 20 μL of the appropriate cocktail to each tube. Flick the tubes to mix the contents then gather the liquid in the bottom of the tube with a short spin down.
- Incubate your digests at 37 °C.
The teaching faculty will leave your digests at 37°C for one hour, then move them to -20°C.
Reagents
- pRSET-IPC (concentration: 0.5 μg / μL )
- NEB buffer
- The buffer you use will depend on the enzymes you use for your confirmation digest, but all NEB buffers are supplied at a 10X concentration.
- NEB enzymes
- The concentration for the enzymes are listed on the product information page of the website.
Next day: Design mutation primers
Previous day: Orientation